6 Modelos Univariados y Multivariados de Volatilidad
6.1 Motivación
En este capítulo discutiremos los modelos de Heterocedasticidad Condicional Autoregresiva (ARCH, por sus siglas en inglés) y modelos de Heterocedasticidad Condicional Autoregresiva Generalizados (GARCH, por sus siglas en inglés) tienen la característica de modelar situaciones como las que ilustra la Figura 6.2. Es decir:
Existen zonas donde la variación de los datos es mayor y zonas donde la variación es más estable–a estas situaciones se les conoce como de variabilidad por clúster–, y
los datos corresponden a innformación de alta frecuencia.
Iniciemos por las bibliotecas necesarias:
library(expm)
library(Matrix)
library(ggplot2)
library(quantmod)
library(moments)
library(dynlm)
library(broom)
library(FinTS)
library(lubridate)
library(forecast)
library(readxl)
library(MASS)
library(rugarch)
library(tsbox)
library(MTS)
library(rmgarch)
library(Rcpp)Para el análisis de temas financieros existe una librería de mucha utilidad llamada quantmod. En primer lugar esta librería permite acceder a datos financieros de un modo muy simple, es posible decargar series financieras desde yahoo, la FRED (Federal Reserve Economic Data), google, etc. Por otro lado, también es una librería que permite realizar gráficos altamente estéticos con unas cuantas líneas de código. Ahora, usaremos datos de Yahoo Finance respecto de la cotización del bitcoin (ticker: “BTC-USD”).
options("getSymbols.warning4.0"=FALSE)
BTC <-getSymbols("BTC-USD", src = "yahoo", auto.assign = FALSE)
BTC <- na.omit(BTC)
chartSeries(BTC,TA='addBBands();
addBBands(draw="p");
addVo();
addMACD()',# subset='2021',
theme="white")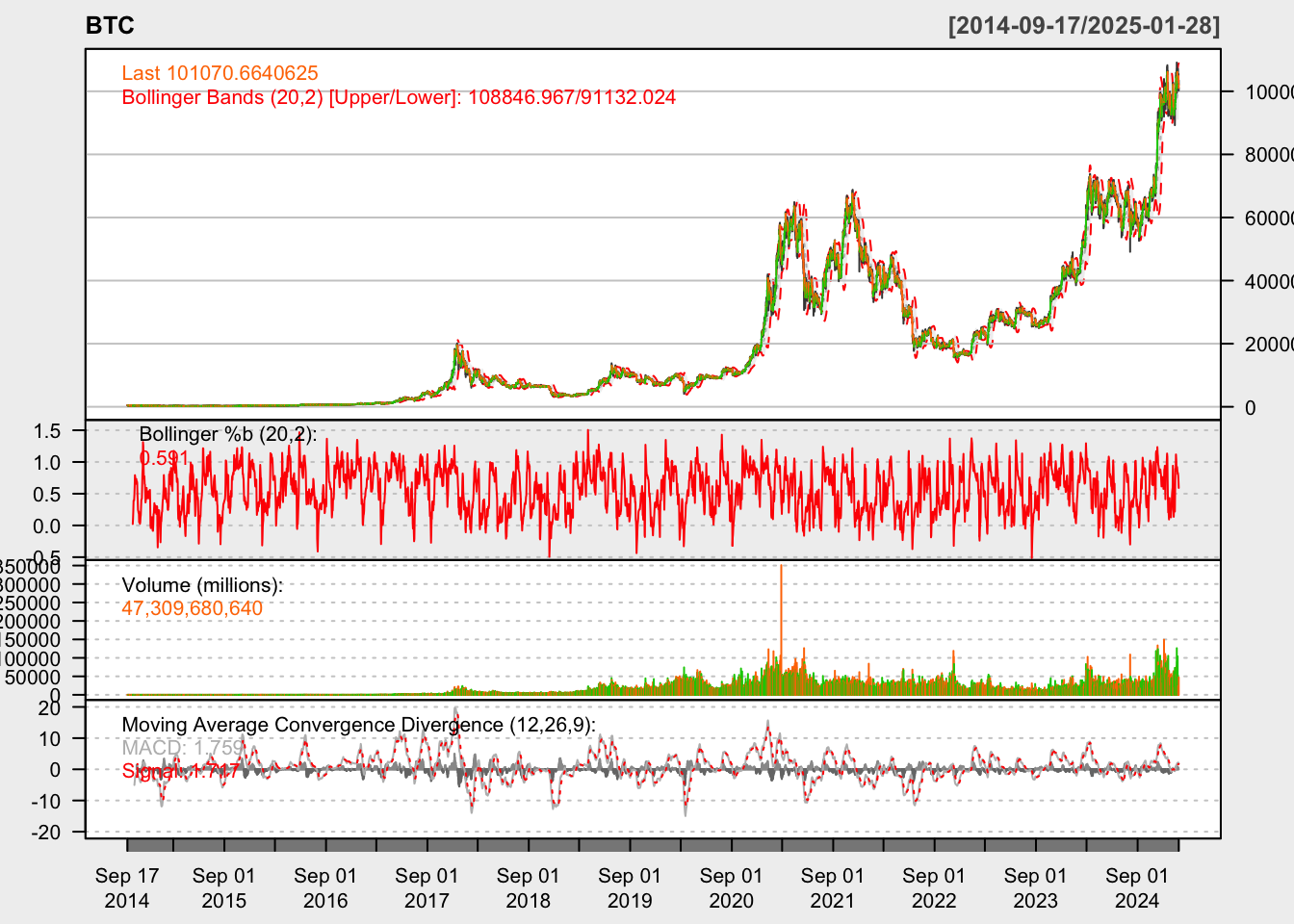
head(BTC)## BTC-USD.Open BTC-USD.High BTC-USD.Low BTC-USD.Close BTC-USD.Volume
## 2014-09-17 465.864 468.174 452.422 457.334 21056800
## 2014-09-18 456.860 456.860 413.104 424.440 34483200
## 2014-09-19 424.103 427.835 384.532 394.796 37919700
## 2014-09-20 394.673 423.296 389.883 408.904 36863600
## 2014-09-21 408.085 412.426 393.181 398.821 26580100
## 2014-09-22 399.100 406.916 397.130 402.152 24127600
## BTC-USD.Adjusted
## 2014-09-17 457.334
## 2014-09-18 424.440
## 2014-09-19 394.796
## 2014-09-20 408.904
## 2014-09-21 398.821
## 2014-09-22 402.152
tail(BTC)## BTC-USD.Open BTC-USD.High BTC-USD.Low BTC-USD.Close BTC-USD.Volume
## 2025-09-24 112007.7 113986.3 111229.6 113328.6 48044595085
## 2025-09-25 113330.2 113541.1 108713.4 109049.3 75528654284
## 2025-09-26 109041.3 110359.2 108729.0 109712.8 57738288949
## 2025-09-27 109707.1 109778.5 109144.3 109681.9 26308042910
## 2025-09-28 109681.9 112375.5 109236.9 112122.6 33371048505
## 2025-09-29 112117.9 114473.6 111590.0 114400.4 60000147466
## BTC-USD.Adjusted
## 2025-09-24 113328.6
## 2025-09-25 109049.3
## 2025-09-26 109712.8
## 2025-09-27 109681.9
## 2025-09-28 112122.6
## 2025-09-29 114400.4Para fines del ejercicio de esta clase, usaremos el valor de la acción ajustado. Esto nos servirá para calcular el rendimiento diario, o puesto en lenguaje de series temporales podemos decir que usaremos la serie en diferencias logarítmicas.
plot(BTC$`BTC-USD.Adjusted`)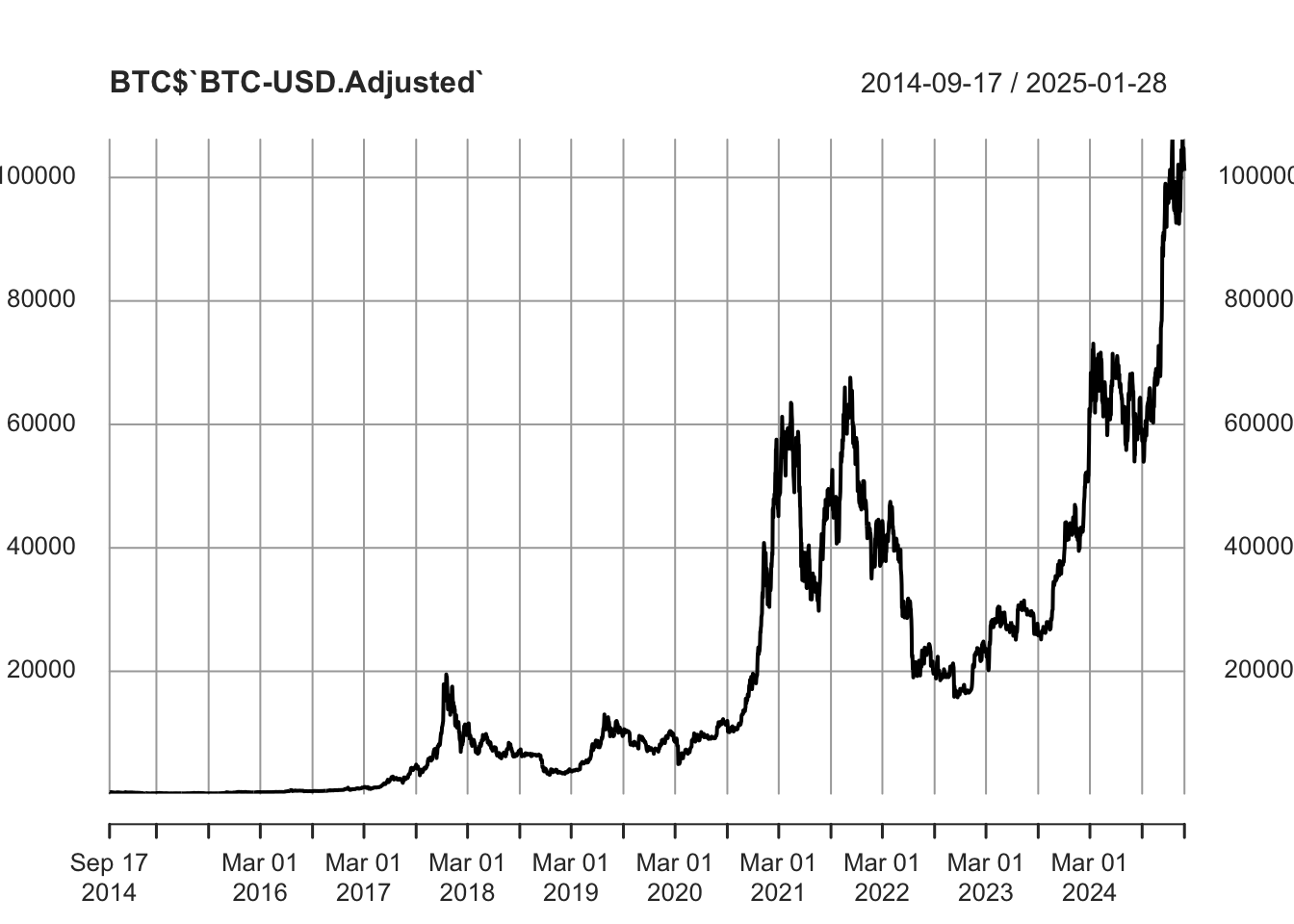
Figure 6.1: Evolución del precio del Bitcoin
Una de las preguntas relevantes al observar la serie en diferencias, es si podríamos afirmar que esta serie cumple con el supuesto de homoscedasticidad. Para ello, la Figura 6.2 muestra que las variaciones en el precio del Bitcoin muestran un escenario en el que no se cumple el supuesto de la homocedasticidad.
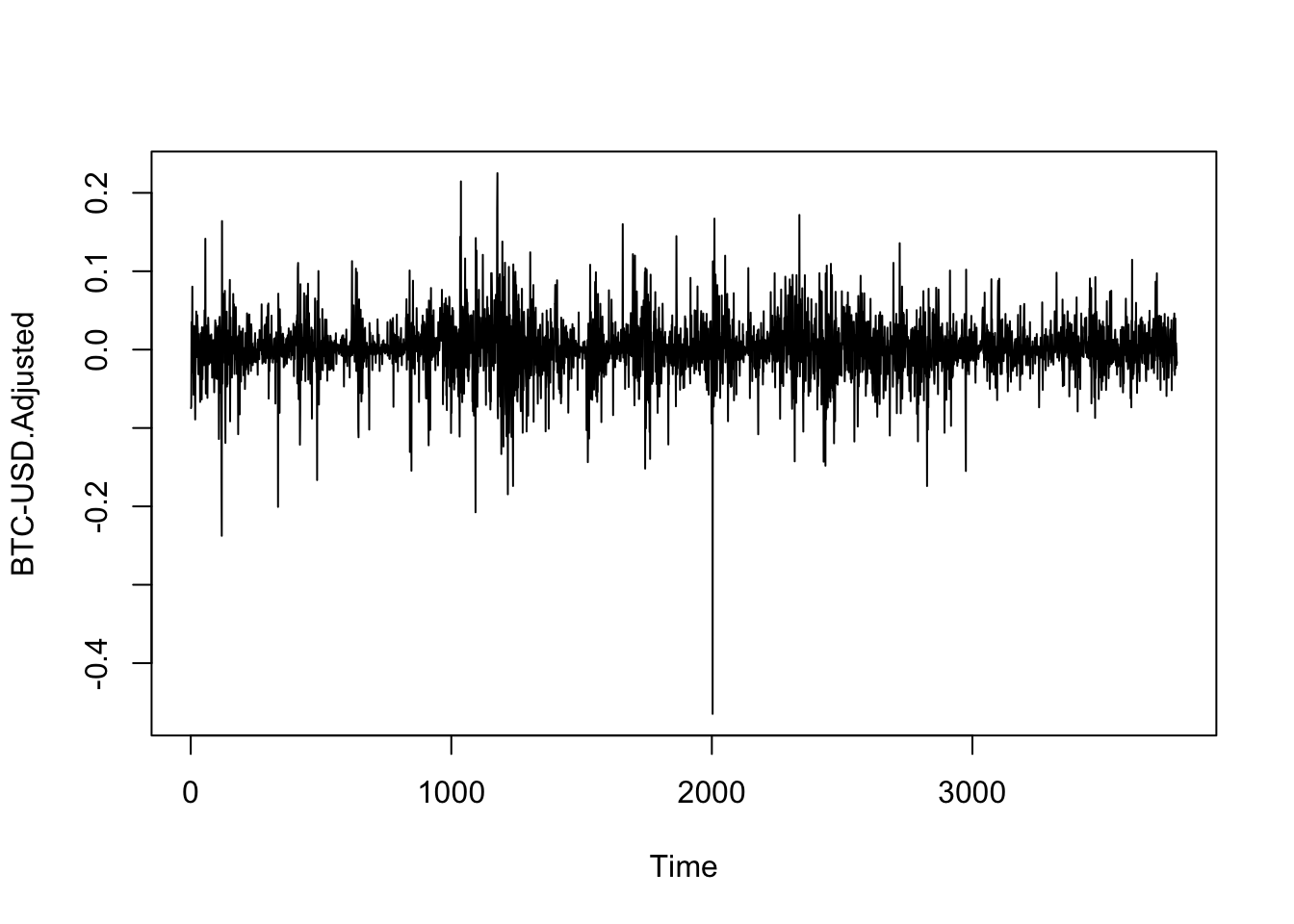
Figure 6.2: Evolución del rendimiento (diferenccias logarítmicas) del Bitcoin
6.1.1 Value at Risk (VaR)
Utilicemos como ejemplo el Valor en Riesgo. Este es básicamente es un cálculo que nos permite estimar el monto que una acción o portafolio podría perder dada una probabilidad \((1-\alpha)\). Supongamos un \(\alpha = 0.05\), de esta forma, la Figura 6.3 ilustra la región de la distribución que consideraríamos como el VaR.
## 5%
## -5.53
qplot(logret , geom = 'histogram') +
geom_histogram(fill = 'lightblue' , bins = 30) +
geom_histogram( aes(logret[logret < quantile(logret , 0.05)]) ,
fill = 'red' , bins = 30) +
labs(x = 'Daily Returns')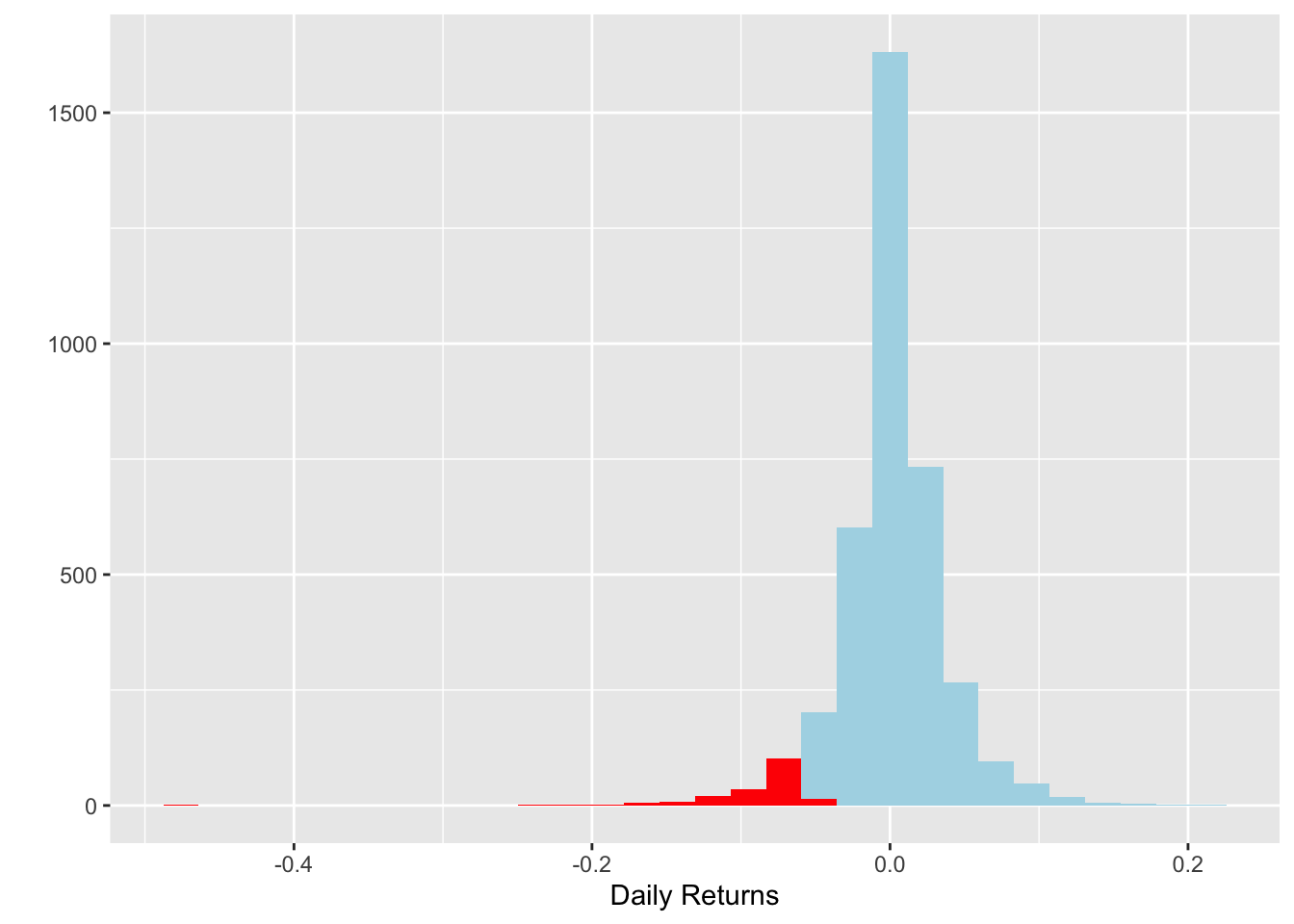
Figure 6.3: Histograma de rendimientos del Bitcoin
Ahora bien, una de las preguntas que nos podemos hacer es si los rendimientos del Bitcoin se aproximan a una distribución normal. Para ello, la Figura 6.4 ilustra esta comparación, de la cual podemos observar que una prueba de normalidad rechaza esa hipótesis–el estadístico Jarque-Bera indica que la serie de rendimientos no tiene una distribución normal–.
normal_dist <- rnorm(100000, mean(logret), sd(logret))
VaR_n <- quantile(normal_dist, 0.05)
ES_n <- mean(normal_dist[normal_dist<VaR])
ggplot()+
geom_density(aes(logret, geom ='density', col = 'returns'))+
geom_density(aes(normal_dist, col = 'normal'))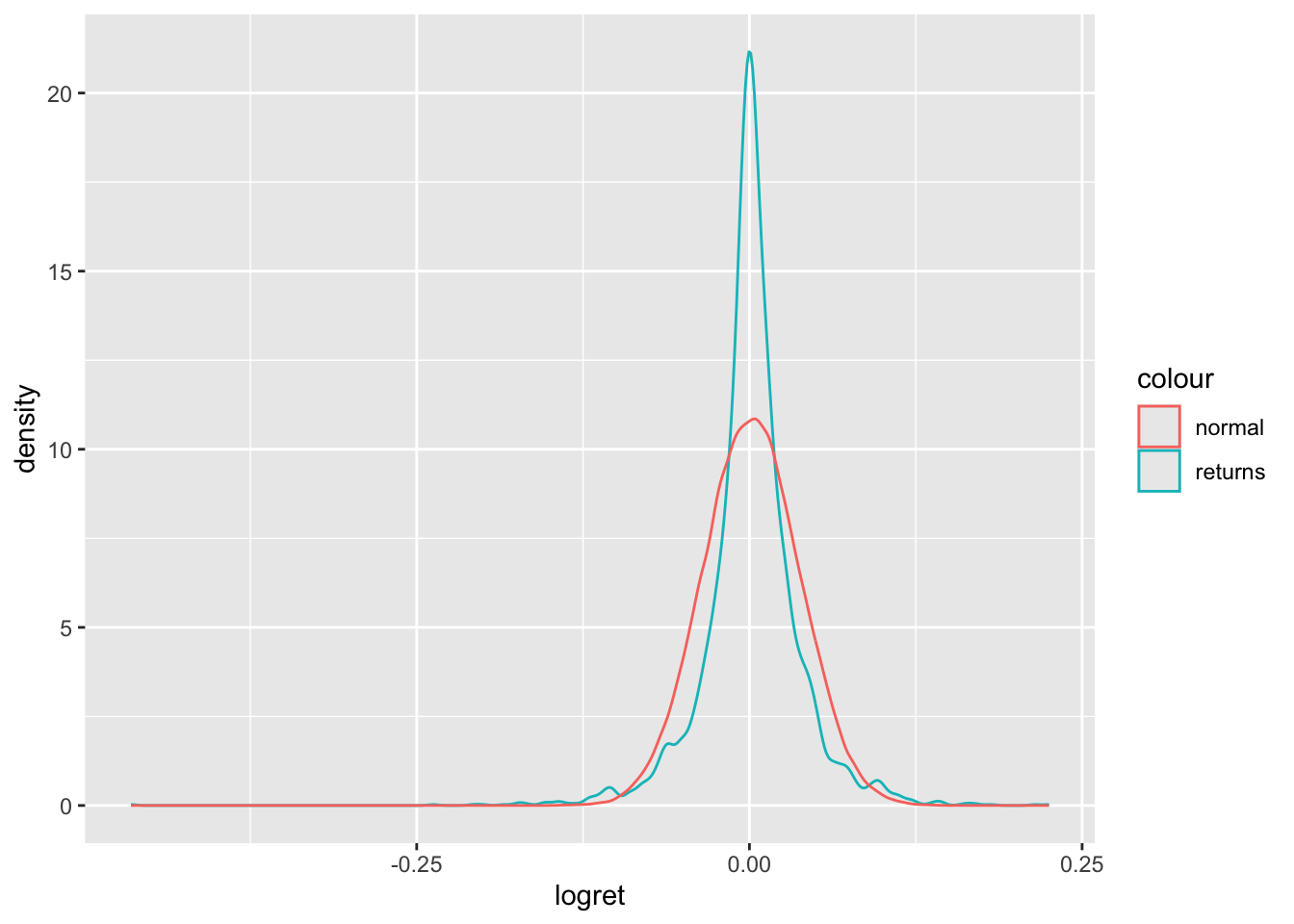
Figure 6.4: Densidad de rendimientos del Bitcoin Vs. una distribución normal
## [1] 14.7## [1] -0.726.2 Prueba de normalidad
\(H_o: K=S=0\)
jarque.test(vector_ret)##
## Jarque-Bera Normality Test
##
## data: vector_ret
## JB = 23316, p-value < 0.00000000000000022
## alternative hypothesis: greater6.3 Modelos ARCH y GARCH Univariados
Para plantear el modelo, supongamos–por simplicidad–que hemos construido y estimado un modelo AR(1). Es decir, asumamos que el proceso subyacente para la media condicional está dada por: \[\begin{equation} X_t = a_0 + a_1 X_{t-1} + U_t \end{equation}\]
Donde \(| a_1 |< 1\) para garantizar la convergencia del proceso en el largo plazo, en el cual: \[\begin{eqnarray*} \mathbb{E}[X_t] & = & \frac{a_0 }{1 - a_1} = \mu \\ Var[X_t] & = & \frac{\sigma^2}{1 - a_1^2} \end{eqnarray*}\]
Ahora, supongamos que este tipo de modelos pueden ser extendidos y generalizados a un modelo ARMA(p, q), que incluya otras variables exógenas. Denotemos a \(\mathbf{Z}_t\) como el conjunto que incluye los componentes AR, MA y variables exógenas que pueden explicar a \(X_t\) de forma que el proceso estará dado por: \[\begin{equation} X_t = \mathbf{Z}_t \boldsymbol{\beta} + U_t \end{equation}\]
Donde \(U_t\) es un proceso estacionario que representa el error asociado a un proceso ARMA(p, q) y donde siguen diendo válidos los supuestos: \[\begin{eqnarray*} \mathbb{E}[U_t] & = & 0 \\ Var[U_t^2] & = & \sigma^2 \end{eqnarray*}\]
No obstante, en este caso podemos suponer que existe autocorrelación en el término de error al cuadrado que puede ser capturada por un proceso similar a uno de medias móviles (MA) dado por: \[\begin{equation} U_t^2 = \gamma_0 + \gamma_1 U_{t-1}^2 + \gamma_2 U_{t-2}^2 + \ldots + \gamma_q U_{t-q}^2 + \nu_t \end{equation}\]
Donde \(\nu_t\) es un ruido blanco y \(U_{t-i} = X_{t-i} - \mathbf{Z}_{t-i} \boldsymbol{\beta}\), $i = 1, 2 ,$. Si bien los procesos son estacionarios por los supuestos antes enunciados, la varianza condicional estará dada por: \[\begin{eqnarray*} \sigma^2_{t | t-1} & = & Var[ U_t | \Omega_{t-1} ] \\ & = & \mathbb{E}[ U^2_t | \Omega_{t-1} ] \end{eqnarray*}\]
Donde \(\Omega_{t-1} = \{U_{t-1}, U_{t-2}, \ldots \}\) es el conjunto de toda la información pasada de \(U_t\) y observada hasta el momento \(t-1\), por lo que: \[\begin{equation*} U_t | \Omega_{t-1} \sim \mathbb{D}(0, \sigma^2_{t | t-1}) \end{equation*}\]
Así, de forma similar a un proceso MA(q) podemos decir que la varianza condicional tendrá efectos ARCH de orden \(q\) (ARCH(q)) cuando: \[\begin{equation} \sigma^2_{t | t-1} = \gamma_0 + \gamma_1 U_{t-1}^2 + \gamma_2 U_{t-2}^2 + \ldots + \gamma_q U_{t-q}^2 \tag{6.1} \end{equation}\]
Donde \(\mathbb{E}[\nu_t] = 0\) y \(\gamma_0\) y \(\gamma_i \geq 0\), para \(i = 1, 2, \ldots, q-1\) y \(\gamma_q > 0\). Estas condiciones son necesarias para garantizar que la varianza sea positiva. En general, la varianza condicional se expresa de la forma \(\sigma^2_{t | t-1}\), no obstante, para facilitar la notación, nos referiremos en cada caso a esta simplemente como \(\sigma^2_{t}\).
Podemos generalizar esta situación si asumimos a la varianza condicional como dependiente de los valores de la varianza rezagados, es decir, como si fuera un proceso AR de orden \(p\) para la varianza y juntándolo con la ecuación (6.1). Bollerslev (1986) y Taylor (1986) generalizaron el problema de heterocedasticidad condicional. El modelo se conoce como GARCH(p, q), el cual se especifica como: \[\begin{eqnarray} \sigma^2_t & = & \gamma_0 + \gamma_1 U_{t-1}^2 + \gamma_2 U_{t-2}^2 + \ldots + \gamma_q U_{t-q}^2 \\ \nonumber & & + \beta_1 \sigma^2_{t-1} + \beta_2 \sigma^2_{t-2} + \ldots + \beta_p \sigma^2_{t-p} \tag{6.2} \end{eqnarray}\]
Donde las condiciones de no negatividad son que \(\gamma_0 > 0\), \(\gamma_i \geq 0\), \(i = 1, 2, \ldots, q-1\), \(\beta_j \geq 0\), \(j = 1, 2, \ldots, p-1\), \(\gamma_q > 0\) y \(\beta_p > 0\). Además, otra condición de convergencia es que: \[\begin{equation*} \gamma_1 + \ldots + \gamma_q + \beta_1 + \ldots + \beta_p < 1 \end{equation*}\]
Usando el operador rezago \(L\) en la ecuación (6.2) podemos obtener: \[\begin{equation} \sigma^2_t = \gamma_0 + \alpha(L) U_t^2 + \beta(L) \sigma^2_t \tag{6.3} \end{equation}\]
De donde podemos establecer: \[\begin{equation} \sigma^2_t = \frac{\gamma_0}{1 - \beta(L)} + \frac{\alpha(L)}{1 - \beta(L)} U_t^2 \end{equation}\]
Por lo que la ecuación (6.2) del GARCH(p, q) representa un ARCH(\(\infty\)): \[\begin{equation} \sigma^2_t = \frac{a_0}{1 - b_1 - b_2 - \ldots - b_p} + \sum_{i = 1}^\infty U_{t-i}^2 \end{equation}\]
6.3.1 Ejemplo ARCH(1)
Hasta ahora, las distribuciones utilizadas para medir el Valor en Riesgo de un activo (Bitcoin, en este caso) asumen que no existe correlación serial en los retornos diarios del activo. Observemos un par de gráficas de la función de autocorrelación para corroborar este hecho–ver la Figura 6.5–.
acf(logret)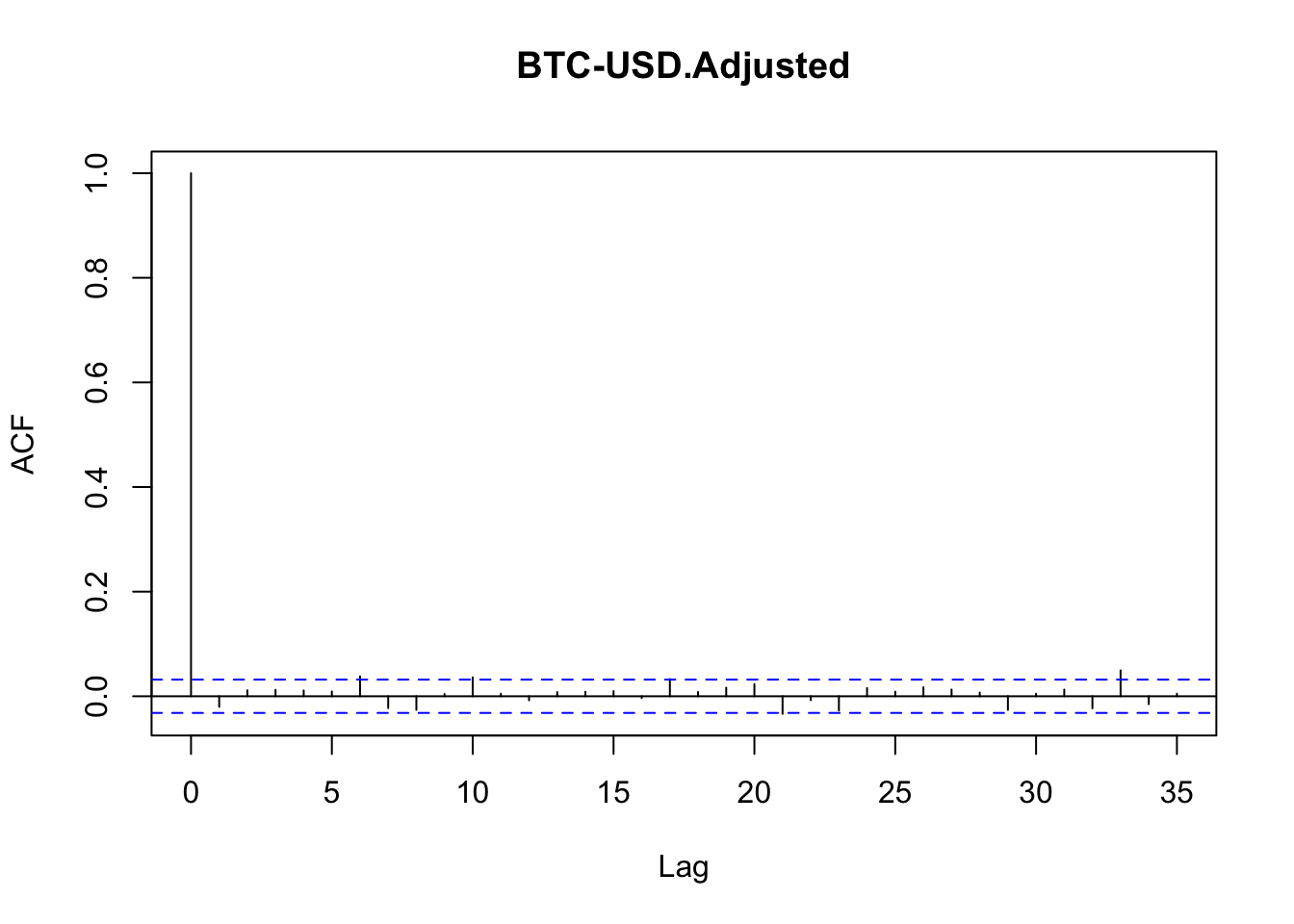
Figure 6.5: Función de autocorrelación parcial de lo rendimientos del Bitcoin
La idea de clusterización de volatilidad asume que períodos de alta volatilidad serán seguidos por alta volatilidad y viceversa. Por esta razón, la función de autocorrelación útil para saber si existen clústers de volatilidad es utilizando el valor absoluto, ya que lo que importa es saber si la serie está autocorrelacionada en la magnitud de los movimientos. La Figura 6.6 muestra el comportamiento de los rendimientos en valor absoluto y la Figura 6.7 la función de autocorrelación parcial.
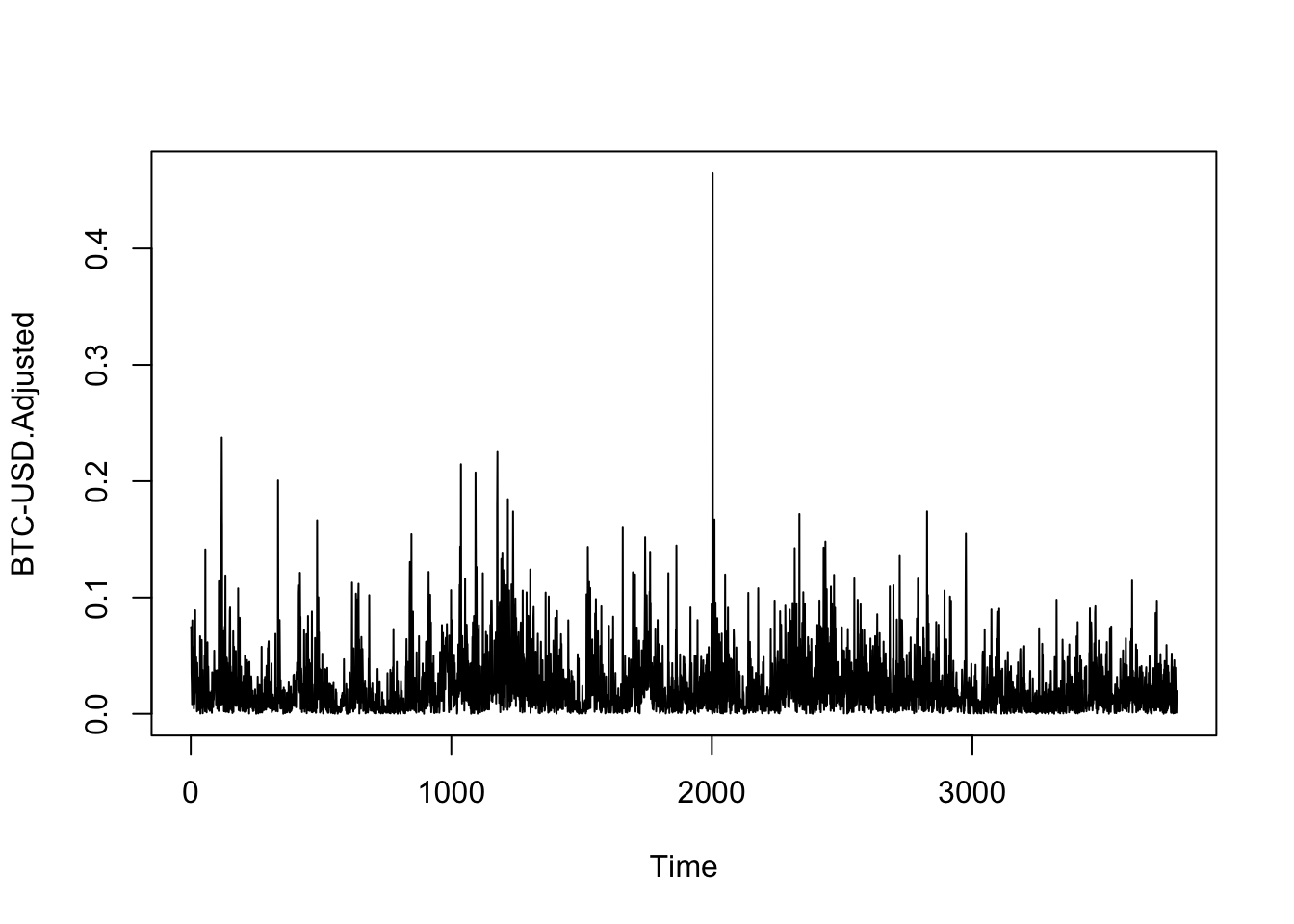
Figure 6.6: Evolución de los rendimientos del Bitcoin en valor absoluto
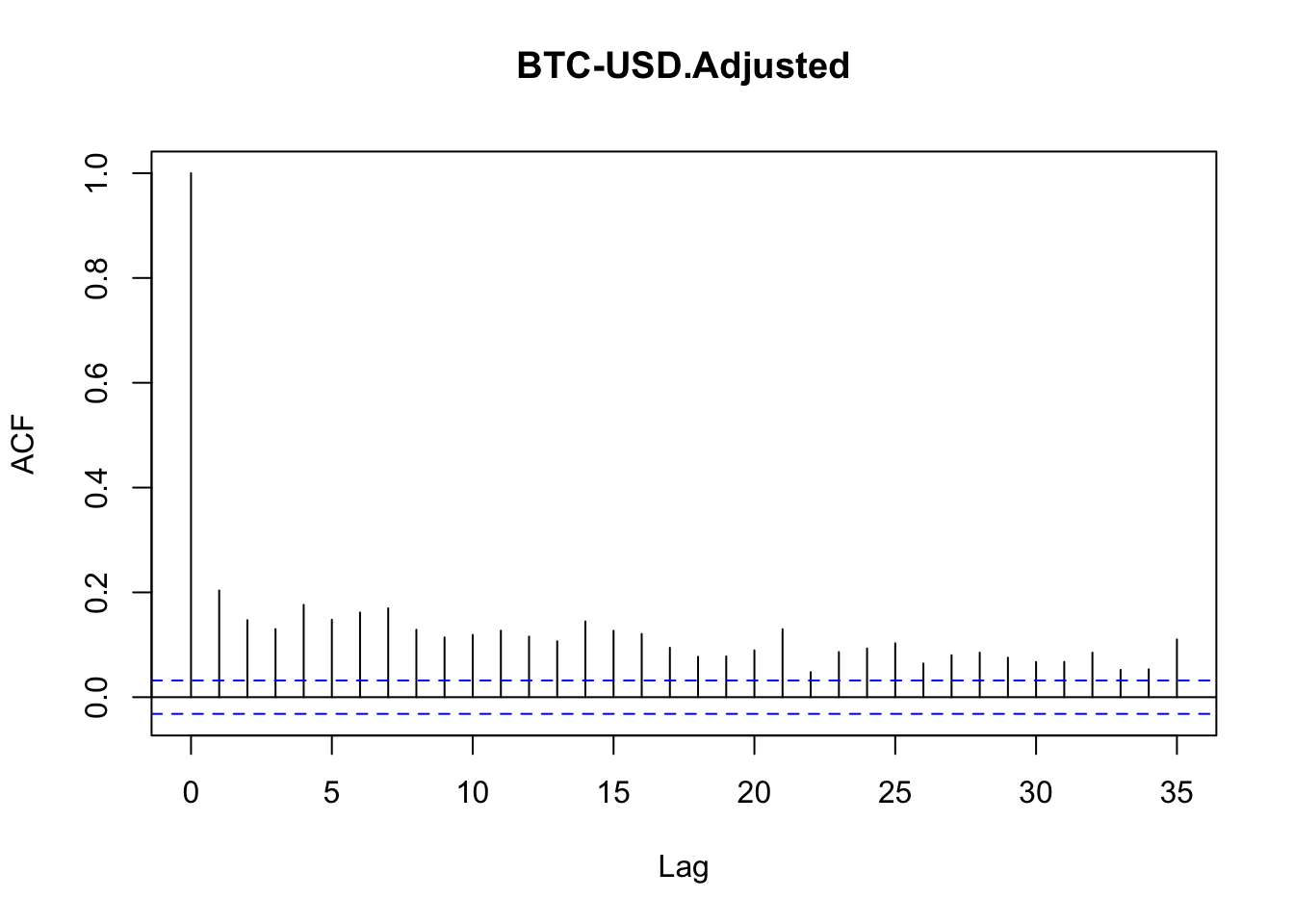
Figure 6.7: Función de autocorrelación parcial de los rendimientos del Bitcoin en valor absoluto
Otra manera de corroborar esta idea es volviendo IID nuestra serie de datos y observar que de este modo se pierde la autocorrelación serial, lo que refuerza la idea de que en esta serie existen clusters de volatilidad.
logret_random <- sample(as.vector(logret), size = length(logret), replace = FALSE)
acf(abs(logret_random))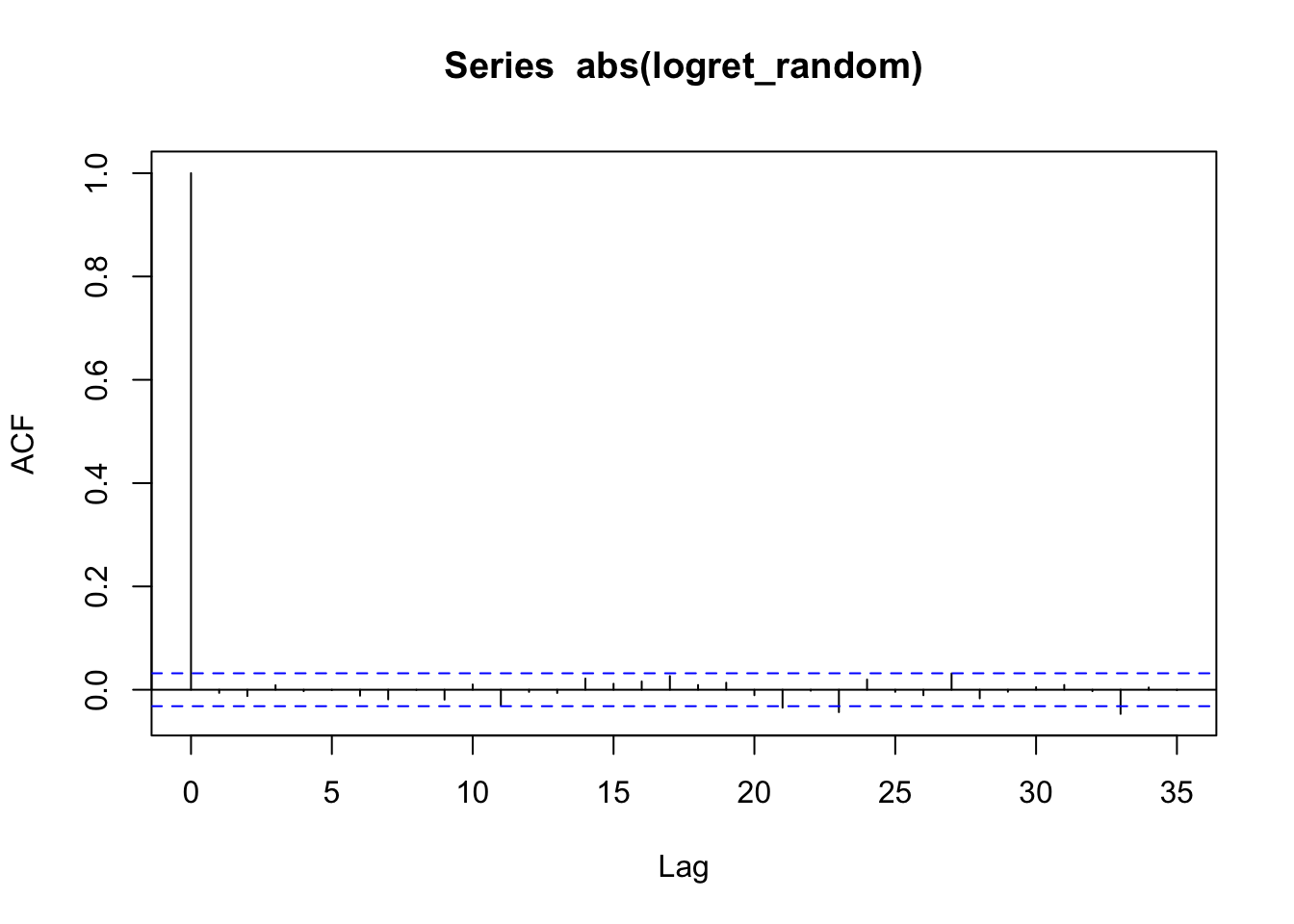
Figure 6.8: Función de autocorrelación parcial de los rendimientos del Bitcoin en valor absoluto
Figure 6.9: Función de autocorrelación parcial de los rendimientos del Bitcoin en valor absoluto
Ahora busquemos una prueba formal. El primer enfoque para comprobar aceptar o rechazar la hipótesis de que necesitamos estimar un ARCH(q) es realizar una prueba de efectos ARCH. De acuerdo con esta, nuestros datos de Bitcoin muestran que se rechaza la hipótesis de no efectos ARCH. Esta prueba resulta del siguiente código de R:
##
## Time series regression with "ts" data:
## Start = 1, End = 4030
##
## Call:
## dynlm(formula = logret ~ 1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.46610 -0.01380 -0.00012 0.01473 0.22375
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.0013702 0.0005618 2.439 0.0148 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03566 on 4029 degrees of freedom##
## Time series regression with "ts" data:
## Start = 2, End = 4030
##
## Call:
## dynlm(formula = ehatsq ~ L(ehatsq))
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.017312 -0.001104 -0.000980 -0.000306 0.216146
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.00110295 0.00007614 14.485 <0.0000000000000002 ***
## L(ehatsq) 0.13164579 0.01561941 8.428 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.004666 on 4027 degrees of freedom
## Multiple R-squared: 0.01733, Adjusted R-squared: 0.01709
## F-statistic: 71.04 on 1 and 4027 DF, p-value: < 0.00000000000000022
acf(ARCH_m$residuals)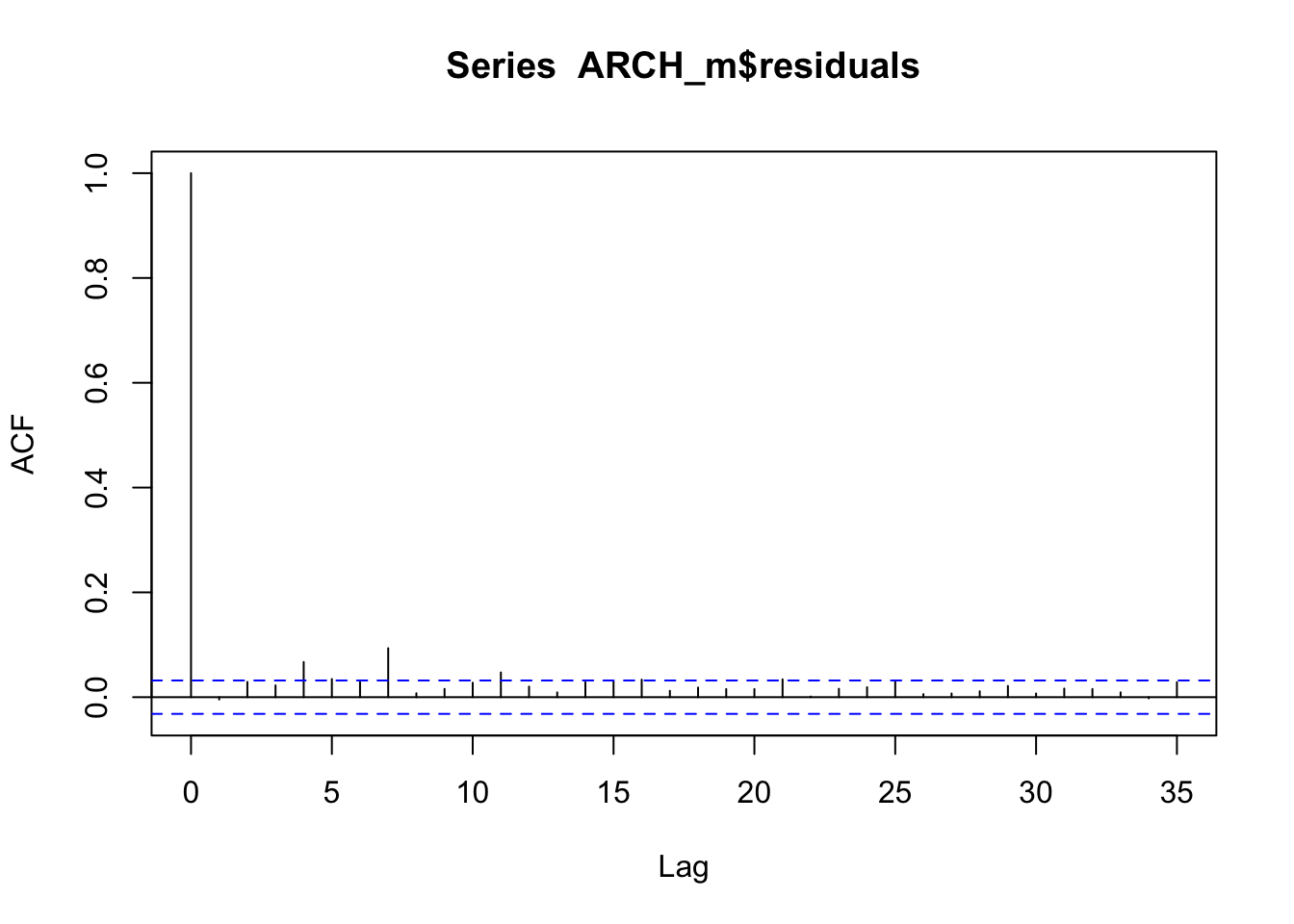
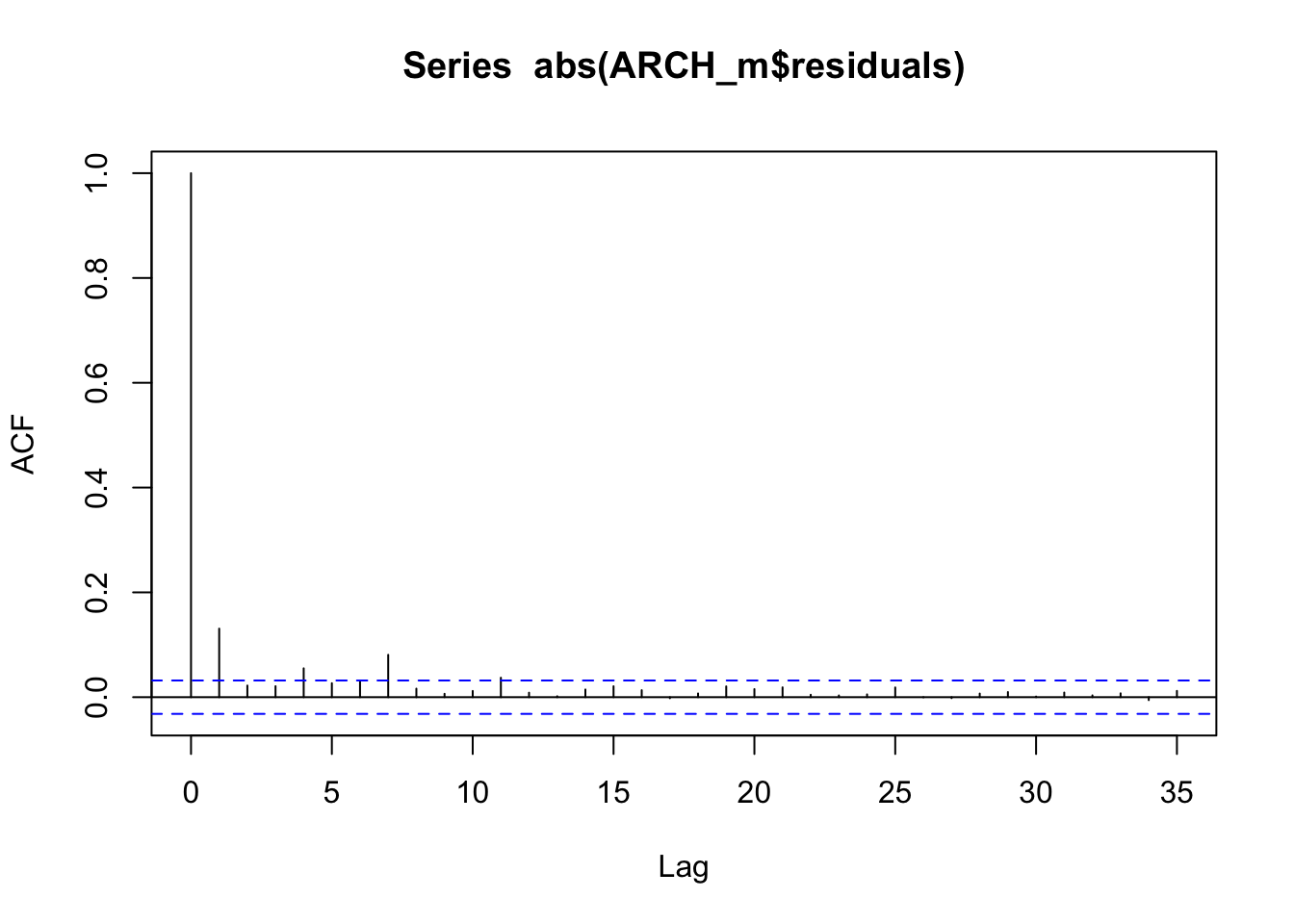
ArchTest(logret, lags = 1, demean = TRUE)##
## ARCH LM-test; Null hypothesis: no ARCH effects
##
## data: logret
## Chi-squared = 69.84, df = 1, p-value < 0.00000000000000022La prueba puede repetirse para diferentes especificaciones de ARCH, sin embargo, para efectos ilustrativos usaremos un ARCH(1). Estimemos un ARCH(1), considerando la siguente especificación:
\[\begin{eqnarray*} Y_t & = & \mu+\sqrt{h_t}\varepsilon_t \\ h_t & = & \omega+\alpha_ih_{t-i}+u_t \\ \varepsilon & \sim & N(0,1) \end{eqnarray*}\]
Considerando que la media es una AR(2), los resultados de esta estimación son los siguientes:
| Parameter | Estimate | Std. Error | t value | Pr(\(>\mid t\mid\)) |
|---|---|---|---|---|
| mu | 0.001642394 | 0.0003553101 | 4.622424 | 3.792818e-06 |
| ar1 | -0.051859993 | 0.0160262284 | -3.235945 | 1.212408e-03 |
| ar2 | -0.001225748 | 0.0132050756 | -0.092824 | 9.260434e-01 |
| omega | 0.001956396 | 0.0004839458 | 4.042593 | 5.286335e-05 |
| alpha1 | 0.730450078 | 0.2140120509 | 3.413126 | 6.422226e-04 |
| shape | 2.347586356 | 0.1135148037 | 20.680883 | 0.000000e+00 |
Notas:
-
Primera línea en negrita como título de la tabla (Markdown no tiene un
\caption{}como LaTeX).
- Bajo el título, se añade un párrafo en itálicas con los valores adicionales (\(\sigma^2\), log-likelihood, AIC, etc.).
- La fila de encabezados va seguida por una fila de separadores (
|:---|---:|etc.) para indicar la alineación a la izquierda, derecha o centro.
- Las celdas con datos numéricos se alinean a la derecha (
:---:o---:) para mantener la estética de los números.
- Si prefieres, puedes omitir la columna de “Notas” y añadir la información directamente en el título de la tabla o en un párrafo posterior.
library(rugarch)
auto.arima(logret)## Series: logret
## ARIMA(2,0,0) with non-zero mean
##
## Coefficients:
## ar1 ar2 mean
## -0.0230 0.0109 0.0014
## s.e. 0.0158 0.0158 0.0006
##
## sigma^2 = 0.001272: log likelihood = 7718.17
## AIC=-15428.33 AICc=-15428.32 BIC=-15403.13
#?ugarchspec
model.spec = ugarchspec( variance.model = list(model = 'sGARCH' ,
garchOrder = c(1, 0)),
mean.model = list(armaOrder = c(2,0)),
distribution.model = "std")
#?ugarchfit
arch.fit = ugarchfit(spec = model.spec , data = logret,
solver = 'solnp')
arch.fit@fit$matcoef## Estimate Std. Error t value Pr(>|t|)
## mu 0.001518650 0.0003334888 4.5538266 0.000005267877
## ar1 -0.053975377 0.0156051658 -3.4588147 0.000542558072
## ar2 -0.002951534 0.0127984640 -0.2306163 0.817612906891
## omega 0.001893703 0.0004694293 4.0340533 0.000054822878
## alpha1 0.783348589 0.2266466146 3.4562554 0.000547736043
## shape 2.335066483 0.1086053044 21.5004828 0.000000000000
boot.garch <- ugarchboot(arch.fit,
method = "Partial",
sampling = "raw", #bootstrap from fitted varepsilon
n.ahead = 1, #simulation horizon
n.bootpred = 100000, #number of simulations
solver = "solnp")
boot.garch##
## *-----------------------------------*
## * GARCH Bootstrap Forecast *
## *-----------------------------------*
## Model : sGARCH
## n.ahead : 1
## Bootstrap method: partial
## Date (T[0]): 4030-01-01
##
## Series (summary):
## min q.25 mean q.75 max forecast[analytic]
## t+1 -0.50164 -0.012865 0.000159 0.014046 0.21377 0.000455
## .....................
##
## Sigma (summary):
## min q0.25 mean q0.75 max forecast[analytic]
## t+1 0.046878 0.046878 0.046878 0.046878 0.046878 0.046878
## .....................6.4 Ejemplo GARCH(0,1)
Estimemos un GARCH(0,1) usando la siguiente especificación: \[\begin{eqnarray*} Y_t & = & \mu+\sqrt{h_t}\varepsilon_t \\ h_t & = & \omega+\beta_i \sigma^2_{t-i}+u_t \\ \varepsilon & \sim & N(0,1) \end{eqnarray*}\]
Considerando que la media es una AR(2), los resultados de esta estimación son los siguientes:
| Parameter | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| mu | 1.743510e-03 | 3.728562e-04 | 4.6760931 | 2.923919e-06 |
| ar1 | -6.104183e-02 | 1.366530e-02 | -4.4669219 | 7.935308e-06 |
| ar2 | -4.231427e-03 | 1.311300e-02 | -0.3226895 | 7.469304e-01 |
| omega | 3.843436e-06 | 6.414905e-08 | 59.9141495 | 0.000000e+00 |
| beta1 | 9.981016e-01 | 3.215075e-05 | 31044.4303 | 0.000000e+00 |
| shape | 2.515980e+00 | 2.796609e-02 | 89.9653552 | 0.000000e+00 |
model.spec = ugarchspec(variance.model = list(model = 'sGARCH' ,
garchOrder = c(0,1)),
mean.model = list(armaOrder = c(2,0)),
distribution.model = "std")
fit.garch.n = ugarchfit(spec = model.spec, data = logret,
solver = "solnp")
fit.garch.n@fit$matcoef## Estimate Std. Error t value Pr(>|t|)
## mu 0.001606593896 0.00035051273602 4.5835536 0.000004571397
## ar1 -0.062258256474 0.01322565519597 -4.7073854 0.000002509142
## ar2 -0.003883239990 0.01272486388570 -0.3051695 0.760237082090
## omega 0.000004347973 0.00000006786633 64.0667151 0.000000000000
## beta1 0.997694999828 0.00004266177719 23386.1565462 0.000000000000
## shape 2.520360403701 0.02668721563123 94.4407404 0.000000000000
boot.garch <- ugarchboot(fit.garch.n,
method = "Partial",
sampling = "raw", #bootstrap from fitted varepsilon
n.ahead = 1, #simulation horizon
n.bootpred = 100000, #number of simulations
solver = "solnp")
boot.garch##
## *-----------------------------------*
## * GARCH Bootstrap Forecast *
## *-----------------------------------*
## Model : sGARCH
## n.ahead : 1
## Bootstrap method: partial
## Date (T[0]): 4030-01-01
##
## Series (summary):
## min q.25 mean q.75 max forecast[analytic]
## t+1 -0.46681 -0.014072 -0.000285 0.014629 0.23776 0.000375
## .....................
##
## Sigma (summary):
## min q0.25 mean q0.75 max forecast[analytic]
## t+1 0.043431 0.043431 0.043431 0.043431 0.043431 0.043431
## .....................6.4.1 Selección GARCH(p,q) óptimo
¿Cómo seleccionamos el órden adecuado para un GARCH(p,q)? Acá una respuesta.
\(Y_t = \mu+\sqrt{h_t}\varepsilon_t\)
\(h_t = \omega+\beta_ih_{t-i}+\alpha_i\varepsilon^2_{t-i}+u_t\)
\(\varepsilon \sim N(0,1)\)
6.4.1.1 Criterios de información
| Criterio | Valor |
|---|---|
| Akaike | -4.083927 |
| Bayes | -4.074035 |
| Shibata | -4.083932 |
| Hannan-Quinn | -4.080410 |
infocriteria(fit.garch.n)##
## Akaike -4.130129
## Bayes -4.120748
## Shibata -4.130134
## Hannan-Quinn -4.1268056.4.1.2 Selección del modelo óptimo
Podemos hacer una búsqueda del mejor modelo de entre varios que probemos en un espectro de hasta un GARCH(4,4). Los resultados son los reportados en el siguiente Cuadro.
| q | p | AIC | Óptimo |
|---|---|---|---|
| 1 | 1 | -10.93647 | 0 |
| 1 | 2 | -10.93657 | 0 |
| 1 | 3 | -10.93799 | 0 |
| 1 | 4 | -10.93727 | 0 |
| 2 | 1 | -10.93579 | 0 |
| 2 | 2 | -10.93607 | 0 |
| 2 | 3 | -10.93743 | 0 |
| 2 | 4 | -10.93510 | 0 |
| 3 | 1 | -10.93524 | 0 |
| 3 | 2 | -10.93510 | 0 |
| 3 | 3 | -10.93765 | 0 |
| 3 | 4 | -10.93645 | 0 |
| 4 | 1 | -10.93840 | 0 |
| 4 | 2 | -10.93935 | 1 |
| 4 | 3 | -10.93924 | 0 |
| 4 | 4 | -10.93816 | 0 |
source("Lag_Opt_GARCH.R")
Lag_Opt_GARCH(ehatsq,4,4)## q p AIC Optimo
## [1,] 1 1 -11.04332 0
## [2,] 1 2 -11.04281 0
## [3,] 1 3 -11.04323 0
## [4,] 1 4 -11.04480 0
## [5,] 2 1 -11.04281 0
## [6,] 2 2 -11.04320 0
## [7,] 2 3 -11.04558 1
## [8,] 2 4 -11.04505 0
## [9,] 3 1 -11.04243 0
## [10,] 3 2 -11.04233 0
## [11,] 3 3 -11.04480 0
## [12,] 3 4 -11.04455 0
## [13,] 4 1 -11.04417 0
## [14,] 4 2 -11.04521 0
## [15,] 4 3 -11.04152 0
## [16,] 4 4 -11.04547 06.4.1.3 Estimación de modelo óptimo
De esta forma, el modelo óptimo es un GARCH(2,4). Los resultados de la estimación son los del Cuadro
| Parameter | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|
| mu | 1.353612e-03 | 3.233488e-04 | 4.186229e+00 | 2.836277e-05 |
| ar1 | -4.916331e-02 | 1.495855e-02 | -3.286636e+00 | 1.013919e-03 |
| ar2 | 7.273432e-04 | 1.385161e-02 | 5.250964e-02 | 9.581226e-01 |
| omega | 2.759072e-05 | 5.151381e-06 | 5.355984e+00 | 8.509188e-08 |
| alpha1 | 1.290996e-01 | 2.165606e-02 | 5.961363e+00 | 2.501419e-09 |
| alpha2 | 1.768468e-07 | 3.676320e-02 | 4.810430e-06 | 9.999962e-01 |
| alpha3 | 6.424436e-08 | 2.663630e-02 | 2.411910e-06 | 9.999981e-01 |
| alpha4 | 3.333343e-02 | 2.238762e-02 | 1.488923e+00 | 1.365077e-01 |
| beta1 | 4.260058e-01 | 2.263614e-01 | 1.881972e+00 | 5.983983e-02 |
| beta2 | 4.105609e-01 | 1.819274e-01 | 2.256730e+00 | 2.402498e-02 |
| shape | 3.183045e+00 | 1.305307e-01 | 2.438541e+01 | 0.000000e+00 |
model.spec = ugarchspec(variance.model = list(model = 'sGARCH',
garchOrder = c(4,2)),
mean.model = list(armaOrder = c(2,0)),
distribution.model = "std")
model.fit = ugarchfit(spec = model.spec , data = logret,
solver = 'solnp')
model.fit@fit$matcoef## Estimate Std. Error t value Pr(>|t|)
## mu 0.0012685546318 0.000306522840 4.138532163482 0.000034953487747735
## ar1 -0.0508002732599 0.014519352729 -3.498797378203 0.000467361595790194
## ar2 -0.0001689612948 0.013496396328 -0.012518993270 0.990011549460776186
## omega 0.0000272650239 0.000003996183 6.822767312297 0.000000000008930412
## alpha1 0.1309492821798 0.021483529738 6.095333670682 0.000000001092094193
## alpha2 0.0000000751803 0.040667601937 0.000001848653 0.999998524988101378
## alpha3 0.0000000331545 0.023565266540 0.000001406922 0.999998877438353917
## alpha4 0.0301388130012 0.021793407782 1.382932550175 0.166685548534062589
## beta1 0.4248488714963 0.240850945920 1.763949358281 0.077740505711282770
## beta2 0.4130629225624 0.198528432363 2.080623503881 0.037468380823419078
## shape 3.1799947162194 0.130027989285 24.456232336713 0.000000000000000000
boot.garch <- ugarchboot(model.fit,
method = "Partial",
sampling = "raw", #bootstrap from fitted varepsilon
n.ahead = 1, #simulation horizon
n.bootpred = 100000, #number of simulations
solver = "solnp")
boot.garch##
## *-----------------------------------*
## * GARCH Bootstrap Forecast *
## *-----------------------------------*
## Model : sGARCH
## n.ahead : 1
## Bootstrap method: partial
## Date (T[0]): 4030-01-01
##
## Series (summary):
## min q.25 mean q.75 max forecast[analytic]
## t+1 -0.25496 -0.008677 0.000343 0.009754 0.19266 0.000308
## .....................
##
## Sigma (summary):
## min q0.25 mean q0.75 max forecast[analytic]
## t+1 0.020669 0.020669 0.020669 0.020669 0.020669 0.020669
## .....................6.4.1.4 Forecasting with GARCH(1,1)
Para realizar pronósticos con la estimación de un GARCH, utilizando la librería rugarch, es necesario utilizar la función ugarchforecast().
model.spec = ugarchspec(variance.model = list(model = 'sGARCH',
garchOrder = c(1,1)),
mean.model = list(armaOrder = c(4,2)),
distribution.model = "std")
model.fit = ugarchfit(spec = model.spec , data = logret,
solver = 'solnp')
spec = getspec(model.fit)
setfixed(spec) <- as.list(coef(model.fit))Esta función precisa como argumentos nuestra estimación del modelo GARCH, con una modificación en la manera en que se presentan los coeficientes, realizada en la última línea del código anterior y que llamamos spec. n.ahead es el número de periodos que vamos a pronosticar, n.roll señala el número de pronósticos móviles que utilizaremos, en caso de que haya más información para realizar el pronóstico. Finalmente damos como input nuestro set de datos y como producto obtendremos el pronostico de Sigma tanto como de la serie.
forecast = ugarchforecast(spec, n.ahead = 12, n.roll = 0, logret)
sigma(forecast)## 4030-01-01
## T+1 0.02073542
## T+2 0.02115149
## T+3 0.02155914
## T+4 0.02195882
## T+5 0.02235096
## T+6 0.02273596
## T+7 0.02311417
## T+8 0.02348593
## T+9 0.02385153
## T+10 0.02421125
## T+11 0.02456535
## T+12 0.02491407
fitted(forecast)## 4030-01-01
## T+1 0.0001171420
## T+2 0.0015336671
## T+3 0.0016039835
## T+4 0.0010158751
## T+5 0.0010431253
## T+6 0.0016260714
## T+7 0.0014569843
## T+8 0.0009160514
## T+9 0.0012164188
## T+10 0.0016834856
## T+11 0.0012699999
## T+12 0.0009041935
forecast##
## *------------------------------------*
## * GARCH Model Forecast *
## *------------------------------------*
## Model: sGARCH
## Horizon: 12
## Roll Steps: 0
## Out of Sample: 0
##
## 0-roll forecast [T0=]:
## Series Sigma
## T+1 0.0001171 0.02074
## T+2 0.0015337 0.02115
## T+3 0.0016040 0.02156
## T+4 0.0010159 0.02196
## T+5 0.0010431 0.02235
## T+6 0.0016261 0.02274
## T+7 0.0014570 0.02311
## T+8 0.0009161 0.02349
## T+9 0.0012164 0.02385
## T+10 0.0016835 0.02421
## T+11 0.0012700 0.02457
## T+12 0.0009042 0.024916.5 Modelos ARCH y GARCH Multivariados
De forma similar a los modelos univariados, los modelos multivariados de heterocedasticidad condicional asumen una estructura de la media condicional. En este caso, descrita por un VAR(p) cuyo proceso estocástico \(\mathbf{X}\) es estacionario de dimensión \(k\). De esta forma, la expresión reducida del modelo o el proceso VAR(p) estará dado por: \[\begin{equation} \mathbf{X}_t = \boldsymbol{\delta} + \mathbf{A_1} \mathbf{X}_{t-1} + \mathbf{A_2} \mathbf{X}_{t-2} + \ldots + \mathbf{A_p} \mathbf{X}_{t-p} + \mathbf{U}_{t} \end{equation}\]
Donde cada uno de las \(\mathbf{A_i}\), \(i = 1, 2, \ldots, p\), son matrices cuadradas de dimensión \(k\) y \(\mathbf{U}_t\) representa un vector de dimensión \(k \times 1\) con los residuales en el momento del tiempo \(t\) que son un proceso puramente aleatorio. También se incorpora un vector de términos constantes denominado como \(\boldsymbol{\delta}\), el cual es de dimensión \(k \times 1\) –en este caso también es posible incorporar procesos determinísticos adicionales–.
Así, suponemos que el término de error tendrá estructura de vector: \[\begin{equation*} \mathbf{U}_t = \begin{bmatrix} U_{1t} \\ U_{2t} \\ \vdots \\ U_{Kt} \end{bmatrix} \end{equation*}\]
De forma que diremos que: \[\begin{equation*} \mathbf{U}_t | \Omega_{t-1} \sim (0, \Sigma_{t | t-1}) \end{equation*}\]
Dicho lo anterior, entonces, el modelo ARCH(q) multivariado será descrito por: \[\begin{equation} Vech(\Sigma_{t | t-1}) = \boldsymbol{\gamma}_0 + \Gamma_1 Vech(\mathbf{U}_{t-1} \mathbf{U}_{t-1}') + \ldots + \Gamma_q Vech(\mathbf{U}_{t-q} \mathbf{U}_{t-q}') (\#eq:M_ARCH) \end{equation}\]
Donde \(Vech\) es un operador que apila en un vector la parte superior de la matriz a la cual se le aplique, \(\boldsymbol{\gamma}_0\) es un vector de constantes, \(\Gamma_i\), \(i = 1, 2, \ldots\) son matrices de coeficientes asociados a la estimación.
Para ilustrar la ecuación @ref(eq:M_ARCH), tomemos un ejemplo de \(K = 2\), de esta forma tenemos que un M-ARCH(1) será: \[\begin{equation*} \Sigma_{t | t-1} = \begin{bmatrix} \sigma^2_{1, t | t-1} & \sigma_{12, t | t-1} \\ \sigma_{21, t | t-1} & \sigma^2_{2, t | t-1} \end{bmatrix} = \begin{bmatrix} \sigma_{11, t} & \sigma_{12, t} \\ \sigma_{21, t} & \sigma_{22, t} \end{bmatrix} = \Sigma_{t} \end{equation*}\]
Donde hemos simplificado la notación de las varianzas y la condición de que están en función de \(t-1\). Así, \[\begin{equation*} Vech(\Sigma_{t}) = Vech \begin{bmatrix} \sigma_{11, t} & \sigma_{12, t} \\ \sigma_{21, t} & \sigma_{22, t} \end{bmatrix} = \begin{bmatrix} \sigma_{11, t} \\ \sigma_{12, t} \\ \sigma_{22, t} \end{bmatrix} \end{equation*}\]
De esta forma, podemos establecer el modelo M-ARCH(1) con \(K = 2\) será de la forma: \[\begin{equation*} \begin{bmatrix} \sigma_{11, t} \\ \sigma_{12, t} \\ \sigma_{22, t} \end{bmatrix} = \begin{bmatrix} \gamma_{10} \\ \gamma_{20} \\ \gamma_{30} \end{bmatrix} + \begin{bmatrix} \gamma_{11} & \gamma_{12} & \gamma_{13} \\ \gamma_{21} & \gamma_{22} & \gamma_{23} \\ \gamma_{31} & \gamma_{32} & \gamma_{33} \end{bmatrix} \begin{bmatrix} U^2_{1, t-1} \\ U_{1, t-1} U_{2, t-1} \\ U^2_{2, t-1} \end{bmatrix} \end{equation*}\]
Como notarán, este tipo de procedimientos implica la estimación de muchos parámetros. En esta circunstancia, se suelen estimar modelos restringidos para reducir el número de coeficientes estimados. Por ejemplo, podríamos querer estimar un caso como: \[\begin{equation*} \begin{bmatrix} \sigma_{11, t} \\ \sigma_{12, t} \\ \sigma_{22, t} \end{bmatrix} = \begin{bmatrix} \gamma_{10} \\ \gamma_{20} \\ \gamma_{30} \end{bmatrix} + \begin{bmatrix} \gamma_{11} & 0 & 0 \\ 0 & \gamma_{22} & 0 \\ 0 & 0 & \gamma_{33} \end{bmatrix} \begin{bmatrix} U^2_{1, t-1} \\ U_{1, t-1} U_{2, t-1} \\ U^2_{2, t-1} \end{bmatrix} \end{equation*}\]
Finalmente y de forma análoga al caso univariado, podemos plantear un modelo M-GARCH(p, q) como: \[\begin{equation} Vech(\Sigma_{t | t-1}) = \boldsymbol{\gamma}_0 + \sum_{j = 1}^q \Gamma_j Vech(\mathbf{U}_{t-j} \mathbf{U}_{t-j}') + \sum_{m = 1}^p \mathbf{G}_m Vech(\Sigma_{t-m | t-m-1}) \label{M_GARCH} \end{equation}\]
Donde cada una de las \(\mathbf{G}_m\) es una matriz de coeficientes. Para ilustrar este caso, retomemos el ejemplo anterior, pero ahora para un modelo M-GARCH(1, 1) con \(K = 2\) de forma que tendríamos: \[\begin{eqnarray*} \begin{bmatrix} \sigma_{11, t} \\ \sigma_{12, t} \\ \sigma_{22, t} \end{bmatrix} & = & \begin{bmatrix} \gamma_{10} \\ \gamma_{20} \\ \gamma_{30} \end{bmatrix} + \begin{bmatrix} \gamma_{11} & \gamma_{12} & \gamma_{13} \\ \gamma_{21} & \gamma_{22} & \gamma_{23} \\ \gamma_{31} & \gamma_{32} & \gamma_{33} \end{bmatrix} \begin{bmatrix} U^2_{1, t-1} \\ U_{1, t-1} U_{2, t-1} \\ U^2_{2, t-1} \end{bmatrix} \\ & & + \begin{bmatrix} g_{11} & g_{12} & g_{13} \\ g_{21} & g_{22} & g_{23} \\ g_{31} & g_{32} & g_{33} \end{bmatrix} \begin{bmatrix} \sigma_{11, t-1} \\ \sigma_{12, t-1} \\ \sigma_{22, t-1} \end{bmatrix} \end{eqnarray*}\]
6.6 Pruebas para detectar efectos ARCH
La prueba que mostraremos es conocida como una ARCH-LM, la cual está basada en una regresión de los residuales estimados de un modelo VAR(p) o cualquier otra estimación que deseemos probar, con el objeto de determinar si existen efectos ARCH –esta prueba se puede simplificar para el caso univariado–.
Partamos de plantear: \[\begin{eqnarray} Vech(\hat{\mathbf{U}}_t \hat{\mathbf{U}}_t') & = & \mathbf{B}_0 + \mathbf{B}_1 Vech(\hat{\mathbf{U}}_{t-1} \hat{\mathbf{U}}_{t-1}') + \ldots \\ \nonumber & & + \mathbf{B}_q Vech(\hat{\mathbf{U}}_{t-q} \hat{\mathbf{U}}_{t-q}') + \varepsilon_t \tag{6.4} \end{eqnarray}\]
Dada la estimación en la ecuación (6.4), plantearemos la estructura de hipótesis dada por: \[\begin{eqnarray*} H_0 & : & \mathbf{B}_1 = \mathbf{B}_2 = \ldots = \mathbf{B}_q = 0 \\ H_a & : & No H_0 \end{eqnarray*}\]
La estadística de prueba será determinada por: \[\begin{equation} LM_{M-ARCH} = \frac{1}{2} T K (K + 1) - Traza \left( \hat{\Sigma}_{ARCH} \hat{\Sigma}^{-1}_{0} \right) \sim \chi^2_{[q K^2 (K + 1)^2 / 4]} \end{equation}\]
Donde la matriz \(\hat{\Sigma}_{ARCH}\) se calcula de acuerdo con la ecuación (6.4) y la matriz \(\hat{\Sigma}_{0}\) sin considerar una estructura dada para los errores.